Wie kam es dazu, dass wir uns diese Frage stellten? Es begann alles mit dem Blockchain-Projekt, das wir im September 2018 starteten. Als Freelancer arbeitete ich mit Krystian Gaus und weiteren Team Mitgliedern von innoBlock an einer Supply Chain Lösung. Während geselligen Blockchain-Stammtisch Abenden, hinterfragte Thorsten Knoll von der Hochschule Rhein-Main den Einsatz von Konsortium Blockchains. Diese Fragestellung begleitete uns und unsere Stammtisch Gespräche immer wieder.
Nach 13 Monaten Entwicklungszeit mit Hyperledger Fabric, Integrationen mit Transport Management Systemen, Web Apps und SAP, beschlossen wir uns näher mit der Frage zu beschäftigen. Das Ergebnis – natürlich ein Blockchain-Meetup in Mainz.
Sind Konsortium Blockchains auch nur verteilte Systeme?
Als Teil des ://webweek19 Programms, hatten wir vorab ein Teaser produziert, um unsere Blockchain-Community in Mainz zu promoten. Danke an das großartige Make Rhein-Main Team!
Grundlagen verteilte Systeme (Distributed Systems)
Wie üblich starteten wir mit einer Begrüßungsrunde, in der sich jeder vorstellte. Schön, dass wir neue Mitglieder an diesem Abend begrüßen durften! Ein Besucher kam extra aus Bad Homburg, da er einige Tage zuvor zufälligerweise einen ://webweek Flyer im Zug gefunden hatte.
Seit dem ich mich mit Blockchain befasse, beobachte ich, dass wir Begriffe nutzen ohne uns näher mit dessen Bedeutung beschäftigen. Das gilt nicht nur für Blockchain und Distributed Ledger.
Wir sprechen von Distributed Ledger Technologien. Von dezentralen Strukturen und digitalem Peer-2-Peer Geld. Von sogenannten DAOs. Meine Beobachtung hierzu – wir werfen zu oft verschiedene Begriffe in einen Topf und nennen es Blockchain. Aus diesem Grund klärten wir an diesem Abend Bedeutungen von Begriffen.
Bevor Krystian von unserer hands-on Erfahrung mit Hyperledger Fabric erzählte, übernahm ich den theoretischen Teil. In den Vorbereitungen für das Meetup habe ich mich mit folgenden Fragen beschäftigt:
- Was für verschiedene Blockchain-Typen gibt es?
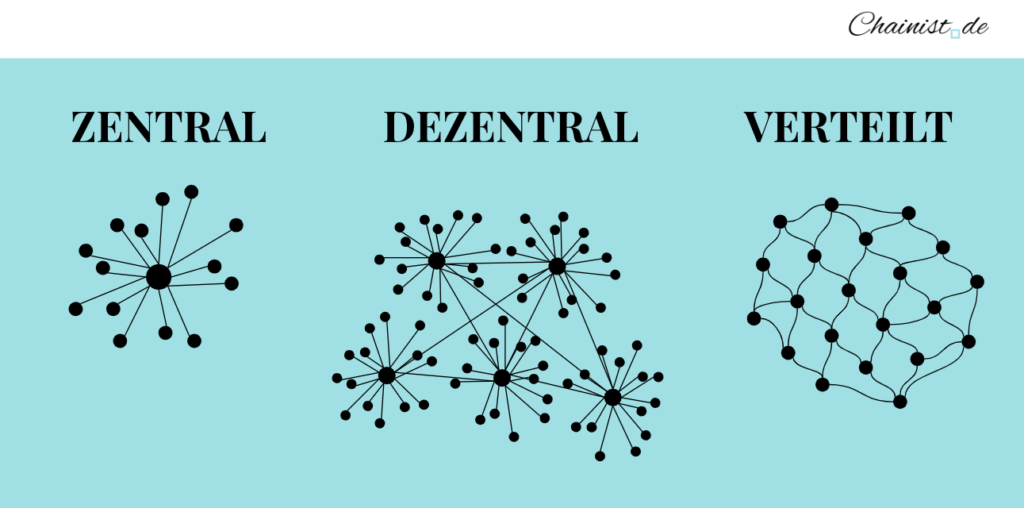
- Wie interpretieren wir zentral, dezentral und verteilt?
- Wie lautet eine Definition von Distributed Systems?
- Warum brauchen wir verteilte Systeme?
- Warum ist das CAP-Theorem so wichtig?
- Was gab es vor Blockchain?
Wichtig finde ich, dass wir eine gemeinsame Definition von Distributed Systems (es gibt keine eindeutige) finden.
…a distributed system is a collection of computing elements each being able to behave independently of each other. A computing element, […] as a node, can be either a hardware device or a software process.
Distributed Systems 3.02, Maarten van Steen, Andrew S. Tanenbaum
A second feature is that users (be they people or applications) believe they are dealing with a single system. This means that one way or another the autonomous nodes need to collaborate.
In einem verteilten System…
a) …verhalten sich Nodes unabhängig von einander
b) …nimmt der Benutzer das System als eines wahr
c) …arbeiten Nodes zusammen
Neben verschiedenen Begriffserläuterungen, versuchte ich in meinem Teil auf alte Konzepte wie Quorum, Paxos, Peer-to-Peer (Übrigens wusstest du, dass Skype mal P2P war?) nicht allzu technisch zu erklären.
Ganz wichtig, versuche das CAP-Theorem zu verstehen. Dann wird dir einiges klar, warum die Skalierungsfrage von DLTs nicht einfach zu beantworten ist bzw. nicht einfach zu lösen ist.
Nachdem wir hoffentlich alle eine gemeinsames Verständnis zu Begriffen hatten ging es weiter mit Krystian.
Sind wir nach 13 Monaten Hyperledger Fabric Entwicklung schlauer geworden?

Krystian gab uns zu Beginn einen kurzen Überblick zu Hyperledger Fabric. Zu dieser Distributed Ledger Technologie hatten wir bereits im November 2018 ein Hyperledger Fabric Workshop in Mainz. Lest euch den Blogbeitrag durch. Übrigens wir bieten auch kostenpflichtige Einführungskurse an. Wir freuen uns auf Anfragen.

Wir sind als Software-Entwickler es gewohnt, dass Programmier-Bibliotheken oder sog. Software Development Kits (SDKs) nicht immer gleich rund laufen. Besonders wenn diese neu sind und noch nicht ausgiebig genutzt wurden. Das trifft auch für Hyperledger Fabric zu.
Der Name „Distributed“ Ledger sagt schon aus, dass es sich um ein verteiltes System handeln sollte. Ob es verteilt ist, hängt ganz alleine davon ab, wie das Blockchain-Netzwerk aufgebaut ist. Lässt du nur eine Node laufen oder sind mehreren Nodes in dem Netzwerk verteilt? Ersteres macht laut Definition von Distributed Systems keinen Sinn.
Erst Solo, dann Kafka, dann Raft
Wir stolperten bei der Netzwerk-Konfiguration von Hyperledger Fabric über die Begriffe Solo und Kafka. Als wir mit dem Projekt starteten, gab es nur diese zwei Optionen, um sogenannte Orderer zu konfigurieren. Solo macht nur Sinn für die Entwicklungsphase. Das ist soweit klar (Aber pssst… wir haben schon von Projekten gehört, die nutzen Solo in Produktion). Nun zu Kafka, es bezeichnet sich als „a distributed streaming platform“. Was bedeutet das nun in unserem Kontext? Daten müssen zwischen verschiedenen Teilnehmern synchron gehalten werden, um Datenkonsistenz über alle Teilnehmer zu gewährleisten. Das ist wichtig, da wir als Endnutzer nicht unterschiedliche Dateneinträge sehen möchten. Wissen alle Nodes, dass du Besitzer von einem Bitcoin oder 0,8 Bitcoin bist? Macht Sinn oder? Da brauchen wir Datenkonsistenz über alle Nodes. Je größer das Netzwerk, desto herausfordernder. Im Falle von Hyperledger Fabric, kümmert sich Apache Kafka darum.
„Each partition is an ordered, immutable sequence of records that is continually appended to—a structured commit log.„
https://kafka.apache.org/intro
Klingt irgendwie sehr bekannt, nicht wahr? Falls nicht, lest doch mal im Bitcoin Whitepaper nach ;). Im Gegensatz zu Bitcoin, braucht Kafka eine zentralistische Struktur. Unsere Reaktion…

Ok, bekannte verteiltes System haben zentrale Stelle, um Datenkonsistenz zu bewahren. Google, AWS, Skype etc. Große Spieler, die über die ganze Welt konsistente Daten brauchen, kann ich nachvollziehen. Aber in einem Blockchain-Netzwerk oder dezentrales Netzwerk, das per se Dezentralität wünscht hat eine zentrale Apache Kafka Stelle? Wirklich?
Die Rettung naht. Während unserer Entwicklungszeit, kam Raft in Spiel. Mit diesem Konsens-Mechanismus, können wir Kafka auf die Ersatzbank verdonnern und erhalten ein dezentraleres Netzwerk. Raft ist eine vereinfachte Form des Paxos Konsens-Algorithmus (es gibt unterschiedliche Varianten). Die Idee von Paxos gibt es seit 1989 (PDF), ich ging hier kurz im ersten Meetup Teil darauf ein.
Wenn Raft seit Fabric 1.4.1 erst offiziell unterstützt wird, wie haben alle Hyperledger Fabric Netzwerke davor gearbeitet, die in Produktion/Proof-of-Concept Modus laufen? Ein Schelm, wer hier etwas weiter denkt ;). Falls du mit Hyperledger Fabric Entwicklern ein Gespräch hast und diesen ins Schwitzen bringen möchtest, die richtige Frage könntest du jetzt stellen.
Gibt es ein Fazit oder eine Antwort?
Krystian und ich haben in unserer Arbeit und Recherchen gesehen, dass die Technologien (in unserem Fall Hyperledger Fabric) immer noch in den Anfängen stehen. Überraschungen sind zu erwarten. Auch wenn diese Überraschungen uns nach dreizehn Monaten sehr irritiert haben und wir aus dem Meetup mit mehr Fragen als Antwort gehen. Wäre ja sonst langweilig! Wir haben erkannt, dass viele Konzepte, die wir heute in Blockchain-Technologien haben seit über 30 Jahren existieren. Und da stellte sich die Frage am Ende des Abends…
Was ist denn das Neue an Blockchains?
„Es ist öffentlich und braucht einen Konsens-Mechanismus wie Proof-of-Work“
Das ist die Antwort von einigen Teilnehmern. Das scheint der Konsens des Abends gewesen zu sein. Diese Aussage hat keiner bestritten bzw. etwas entgegenzusetzen.
Wir haben in den Diskussionen beobachtet, dass es wichtig ist, Begriffe zu klären und zu definieren, damit wir einen gemeinsames und besseres Verständnis von Dingen erhalten. Ansonsten reden wir aneinander vorbei.
Ich hoffe, dass ihr einen denkanstoßenden Abend hattet. Wir sehen uns am 3. Dezember 2019 zum nächsten Meetup wieder. Wir werden auf das Jahr 2019 zurückblicken und Ideen für das Jahr 2020 für unsere Blockchain-Community sammeln.
Die Slides von Krystian und mir findest du nachfolgend. Auf dem letzten Slide, findest du alle Links zu Quellen.
https://docs.google.com/presentation/d/1GFd3wcY-pqTd14gfdFraB4pox9iYk8tL5KXQN3MVFKA/edit?usp=sharing
Wichtige Quellen gleich hier:
- Distributed Systems, 3rd Edition
- Paxos Made Simple (PDF)
- CAP-Theorem Twelve Years Later
- Meet the Man Who’s Rewiring Google From the Inside Out
- The Raft Consensus Algorithm
- Bringing up a Kafka-based Ordering Service
- Apache Kafka for beginners – What is Apache Kafka?
